Why Personal Clouds and Midata are Good for Business
I’ve long been an advocate of Craig Burton’s thesis that ‘VRM’ and the inevitable shift towards ‘personal clouds’ will be good for the organisations. His excellent overview here includes some real gems, not least ‘Baking core competency in an API-set is an economic imperative’.
And i’ve also noted the slow pace of the UK.gov Midata programme aimed at helping individuals gain access to the data held on them by their suppliers in a form that they can re-use. It is clear that the majority of organisations are not exactly rushing to deliver on that, one assumes because they perceive much more threat than opportunity in doing so. I don’t see that changing in the immediate future, and note that many are now focused on how they can deliver Midata, still within their own context. The back-stop legislation being proposed is unlikely to change that stance. Similar initiatives elsewhere will probably run on similar lines, although USA probably has a strong approach in working with semi-public sector data managers whose hand can be more pro-actively forced.
Given that, i’ve tried to set out below a view on why taking a more pro-active stance on Midata would be a good thing for organisations, and merging that with some thoughts on how this will enable that focus on core competencies, and what that will look like in practical deployment terms.
I’ll do so using visualisations of a ‘CRM’ data record; how that is supposed to look, how it usually does look in practice, and what it will look like as the above scenarios deliver in the mid term.
The first visual below shows a theoretical view of what a customer record would look like in the data warehouse sitting behind the customer management systems of pretty much any large business to consumer organisation – from bank, to retail, to utility, to public sector and health provider. Having this in place allows the organisation to run all of the customer management processes they want, to a high standard. The main building blocks of the record are The Customer, The Product/ Service, The Outlet (sales channel), The Relationship between Customer and Product, The Offer (being made to the customer/ potential customer), and The Customer-Organisation Interaction(s). Each sector will have minor (10%) nuances around the detail, and differing terminology in places, but the big building blocks remain the same.
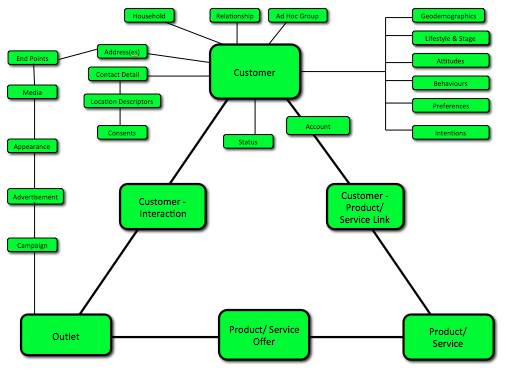
However, there’s a problem……
The second visual (built up from many deep dive assessments) is more illustrative of the reality, the colours being driven, in traffic light style, by data quality, which includes whether it exists in the system at all, along with other classic data quality metrics such as recency/ source of update, completeness, compliance etc.
To avoid too much time analysing the detail – the short version is that many organisations are running their customer management processes on very poor quality fuel.
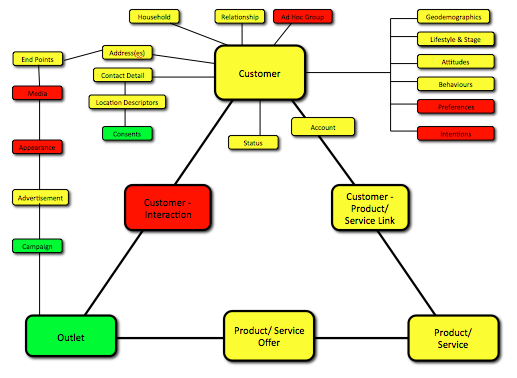
So what’s going to happen to change that; because the above has been the case for the last 20 years?
The short answer is Personal Clouds (aka Personal Data Services). These will enable the individual to take on a significant chunk of the data management task, and be happy to do so because they will benefit hugely from doing so. Many people will only be vaguely aware that they even have such a thing; the personal cloud(s) will be just a small component of a wider proposition, like a SIM card is to a phone. The recently launched Cheap Energy Club is a good example of the above – a mini personal cloud buried within a much more compelling customer and supplier proposition.
The third visual below is a stab at how the customer record, as we know it now, will change over time. What i’m suggesting is that the significant majority of the customer record will actually be managed by the customer. And that this customer managed portion will itself sub-divide into My Data* (volunteered personal information brought together in a personal cloud by the individual), and Our Data** (co-created/ co-owned data currently managed by the organisation and, over time increasingly made available to the individual).
* For more on this provenance based categorisation of the data around in individual see this post from a few years back covering My Data, Your Data, Our Data, Their Data and Everybody’s Data.
** Confusingly what i’m calling Our Data, UK.gov calls ‘Midata‘. My Data and Midata should not be confused; the former I don’t need to retrieve from somewhere, it’s mine in the first place..
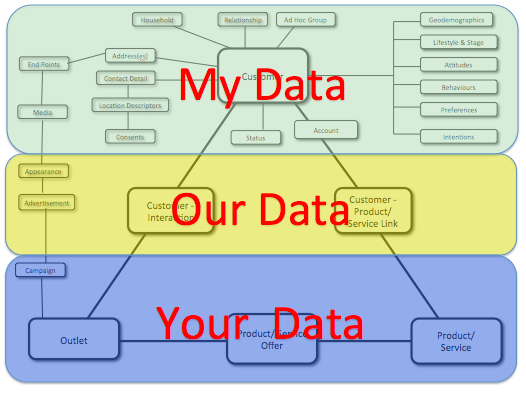
Firstly, there will be huge chunks of cost taken out of current customer information management activity. Many organisations spend tens or hundreds of millions of pounds per year managing customer information.
Secondly, data (fuel) quality will be much improved, enabling the option to run much more efficient and effective customer management processes – across all aspects of the customer lifecycle. To bring this to life, this becomes the mythical ‘360 degree view of the customer’; i.e. the customer has data from across their supply base, not just the single organisational silo view that is the current fuel.
Thirdly – look at what’s left for the organisation to manage…, the data about their products/ services, their outlets (channels), their product/ service offers, and their marketing campaigns. i.e. their core competencies. That’s a scary but ultimately winning proposition for organisations – ‘give up control of something that you value highly but has a high degree of toxicity (customer data), in order to focus much more on that which you do best’.
To round that off, and return to the core point from Craig, we have a fourth visual. The API’s….Each of those three buckets of data thrive on being connected to each other in secure ways, much more so than they do when they are combined. And thrive further still when ‘apps’ and utilities can be pointed at then, or used to bridge them.
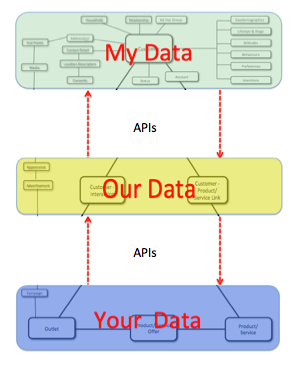
If these API’s are designed and deployed well, then the personal data eco-system thrives, and the individual genuinely becomes the point of integration and origination for data about them. In turn, this architecture is also the only really viable one for ‘The Internet of My Things’, which will further turbo-charge the individual and their personal data capabilities.
There’s much more to write on this, including which ‘apps’ are on their way, and how organisations can enable their processes in this way. I’ll save that for another day.